
Synthetic data is reshaping how organizations handle privacy and data-sharing challenges. By creating artificial datasets that mimic real data patterns, it avoids directly exposing personal information. Compared to anonymization, synthetic data offers a fresh approach to safeguarding privacy while maintaining utility. However, it’s not without risks, including re-identification vulnerabilities and legal uncertainties.
Key Points:
- What is Synthetic Data? Artificial data that mirrors real data’s statistical properties without linking to actual individuals.
- Privacy Benefits: Reduces exposure of sensitive personal data and complies more easily with regulations like GDPR and HIPAA.
- Challenges: Risks include re-identification attacks, bias in data generation, and gaps in legal frameworks.
- Real Data vs Synthetic Data: Real data offers higher accuracy but carries significant privacy and compliance risks.
Bottom Line: Synthetic data is a promising tool for balancing privacy and utility, but organizations must address its limitations, especially in terms of bias and security, to use it effectively.
Synthetic Data Explained: AI Training Without Privacy Risks
sbb-itb-a8d93e1
1. Synthetic Data
This section explores how synthetic data helps safeguard privacy, supports regulatory compliance, and grapples with challenges like re-identification risks and fairness concerns.
PII Exposure
Unlike traditional anonymization, synthetic data doesn’t rely on masking or removing identifiers. Instead, it creates entirely new records that replicate statistical patterns without exposing real individuals. This approach allows organizations to share insights or train models without compromising sensitive personal information.
When paired with Differential Privacy (DP), synthetic data enhances privacy protections. As Dwork and Roth explain:
"the outcome of a differentially private analysis or data release should be roughly the same whether or not any single individual’s data was included in the input dataset".
DP ensures individual contributions remain undetectable, offering a robust mathematical safeguard. However, without such protections, generative models can unintentionally memorize specific details from training data, potentially breaching privacy.
Compliance
Synthetic data offers a way for organizations to navigate privacy regulations like HIPAA, GDPR, and CCPA by minimizing exposure to personally identifiable information (PII). Under GDPR, fully synthetic data is considered anonymous (Recital 26) and exempt from stringent data protection rules, provided the re-identification risk is minimal. However, partially synthetic or hybrid datasets that retain real identifiers must still comply with GDPR’s principles, such as lawfulness and purpose limitation under Article 5.
To meet these standards, organizations need to report unwanted phone calls and define the privacy unit – whether at the record or user level – and rigorously test for vulnerabilities like membership inference or reconstruction attacks. For example, in December 2022, the International Organization for Migration (IOM) and Microsoft released the Global Victim-Perpetrator Synthetic Dataset. This dataset, derived from human trafficking case records, used synthetic generation to protect victims’ identities while enabling research.
Despite these advantages, risks during the data generation process remain a concern.
Risk of Re-identification
While synthetic data avoids the direct one-to-one links between real and synthetic records that traditional anonymization methods struggle with, re-identification risks still exist. Generative models that lack strong privacy safeguards can memorize and inadvertently reveal individual data points.
In May 2025, the ReconSyn attack demonstrated this vulnerability by recovering 78%-100% of outliers from datasets like MNIST and Census. This showed that even models designed with Differential Privacy can leak sensitive details if similarity heuristics remain unchecked. This highlights a crucial issue: privacy must be embedded in the generative process, not just evaluated in the final dataset.
Bias and Fairness
Synthetic data can help address imbalances in datasets by generating examples for underrepresented groups, creating more equitable training sets and improving model performance. However, this introduces a dilemma. As Emiliano De Cristofaro points out:
"Protecting privacy inherently means you must ‘hide’ vulnerable data points like outliers… if one tries to use synthetic data to upsample an under-represented class… they will inherently need to choose between either privacy or utility".
This trade-off between privacy and fairness becomes especially pronounced when up-sampling underrepresented groups. Balancing these competing priorities remains a central challenge in leveraging synthetic data effectively.
2. Real Data
Real data, unlike its synthetic counterpart, is directly tied to individuals, which significantly increases legal and regulatory challenges. Each record in a real dataset represents a specific person, making it vulnerable to exposure risks that traditional anonymization methods often fail to mitigate.
PII Exposure
Real datasets frequently include direct identifiers (like names or Social Security numbers) and quasi-identifiers (such as ZIP codes, birth dates, or gender). These quasi-identifiers can often be linked with external data sources to pinpoint identities. Simply removing names or Social Security numbers doesn’t guarantee privacy. As Steven M. Bellovin, a Professor of Computer Science at Columbia University, points out:
"Anonymization [is] a subtractive technique incurring not only poor privacy results, but also lackluster utility".
Certain datasets, like location histories or browsing patterns, are particularly risky because they are inherently sparse – meaning most individual records are unique and easily identifiable. For instance, modern data brokers like Acxiom reportedly hold around 1,500 pieces of information about each consumer, making it even easier to uniquely identify someone. In a dataset containing 1.5 million people, just four spatio-temporal data points can uniquely identify 95% of individuals.
This heightened risk of exposing personally identifiable information (PII) also brings about significant regulatory challenges.
Compliance
Handling real data comes with strict regulatory obligations, particularly under U.S. privacy laws. For example, the California Consumer Privacy Act (CCPA) requires businesses to meet several consumer rights, including responding to requests within 45 days, verifying identities (which itself can create privacy risks), and managing rights to access, delete, correct, or opt-out of data collection. The CCPA applies to for-profit businesses earning over $25 million annually or those dealing with the personal data of 100,000 or more California residents.
Data breaches under the CCPA can result in liabilities of up to $750 per affected individual. Meanwhile, HIPAA regulations demand the removal of all identifiers to achieve "anonymization", but this process often reduces the dataset’s usefulness for research or machine learning.
The compliance burden becomes even heavier due to real data’s vulnerability to re-identification.
Risk of Re-identification
Real datasets are particularly susceptible to linkage attacks, where anonymized records are matched with publicly available data to reveal identities. The unique combinations of attributes in real datasets make it easy to single out individuals.
For example, in 2009, researchers Arvind Narayanan and Vitaly Shmatikov successfully de-anonymized a supposedly “de-identified” Netflix movie rating dataset by cross-referencing it with public IMDb data. Similarly, the New York Times managed to re-identify then-President Donald Trump’s tax information by analyzing anonymized public IRS data about top earners. These cases highlight how traditional anonymization methods often fail to provide adequate privacy protections for real data.
Pros and Cons
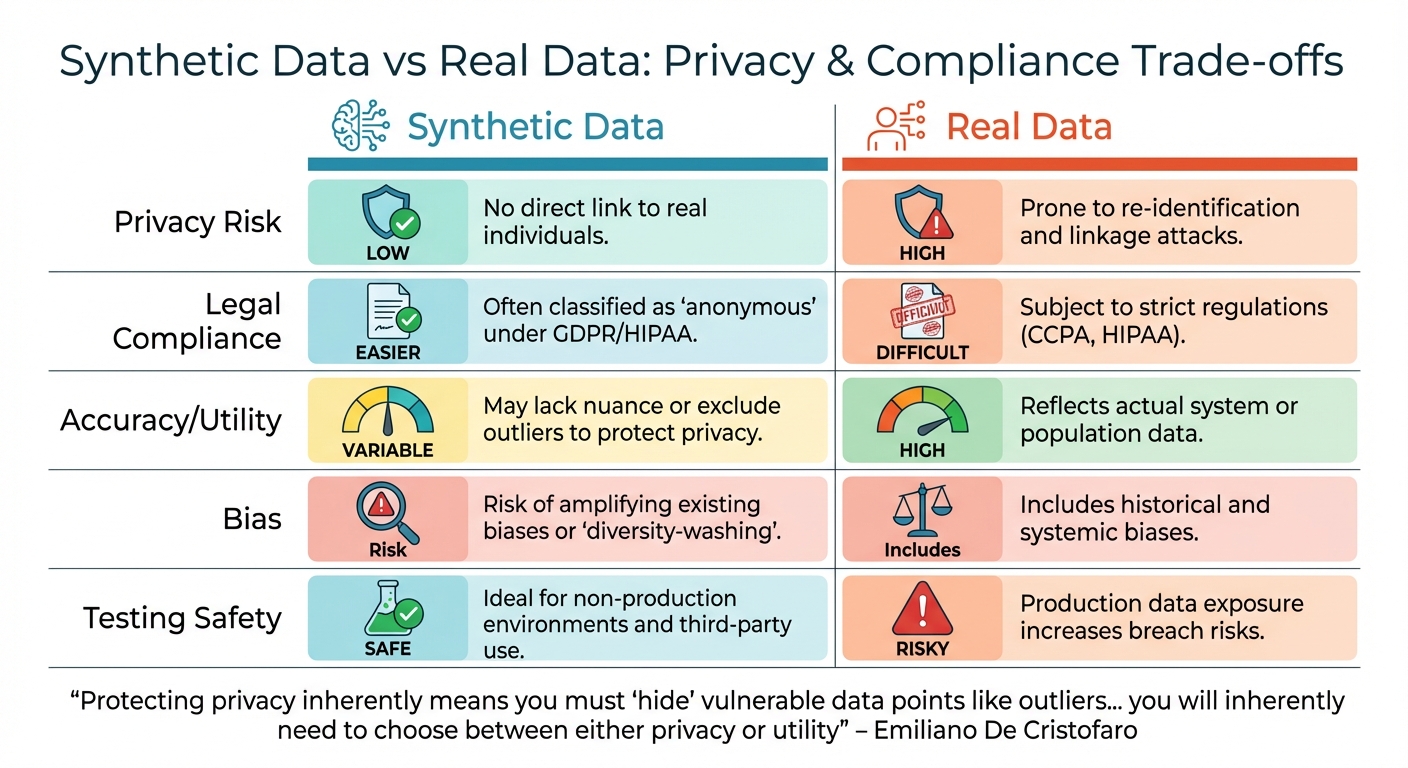
Synthetic Data vs Real Data: Privacy, Compliance, and Accuracy Comparison
When it comes to synthetic and real data, each has its own set of privacy strengths and weaknesses that organizations must carefully consider. The choice between the two often hinges on factors like specific use cases, regulatory requirements, and risk tolerance. Here’s a closer look at how these trade-offs play out, particularly in the legal and ethical landscape.
Synthetic data provides a strong layer of privacy by creating records that are not directly tied to real individuals. This eliminates the risk of direct re-identification that often challenges anonymized real datasets. As DataCamp explains:
"Unlike anonymization techniques that can sometimes be reversed, synthetic data is generated from scratch".
However, synthetic data isn’t without flaws. It can still be susceptible to membership inference attacks and may unintentionally amplify biases by omitting rare but valuable outliers.
Real data, on the other hand, mirrors real-world complexities with high accuracy. But it’s far more vulnerable to re-identification and linkage attacks. Additionally, real datasets must comply with stringent regulations like the CCPA and HIPAA, making their use and management more challenging.
| Aspect | Synthetic Data | Real Data |
|---|---|---|
| Privacy Risk | Low; no direct link to real individuals | High; prone to re-identification and linkage attacks |
| Legal Compliance | Easier; often classified as "anonymous" under GDPR/HIPAA | Difficult; subject to strict regulations |
| Accuracy/Utility | Variable; may lack nuance or exclude outliers to protect privacy | High; reflects actual system or population data |
| Bias | Risk of amplifying existing biases or "diversity-washing" | Includes historical and systemic biases |
| Testing Safety | Safe for non-production environments and third-party use | Risky; production data exposure increases breach risks |
This table underscores the delicate balance between privacy, utility, and regulatory compliance. As Emiliano De Cristofaro from the University of California, Riverside, points out:
"Protecting privacy inherently means you must ‘hide’ vulnerable data points like outliers… you will inherently need to choose between either privacy or utility".
This trade-off lies at the heart of data strategy decisions, especially for industries where privacy concerns are paramount.
Legal and Ethical Trade-offs
When considering the privacy benefits and risks of synthetic data, it’s crucial to dive into the legal and ethical trade-offs involved. U.S. privacy laws, like HIPAA and FERPA, weren’t designed to address synthetic data, leaving businesses navigating a legal gray area. A core issue is whether synthetic data should be categorized as personal data, a question that carries significant legal weight.
The responsibility lies heavily on businesses to prove compliance. Research shows that 99.98% of individuals in a supposedly de-identified U.S. dataset could be re-identified using just 15 demographic attributes. Attorney Mark D. Metrey from Hudson Cook LLP highlights the challenge:
"The risk of re-identification challenges the assumption that de-identified or synthetic data is exempt from privacy laws".
Court rulings further underscore the complexity. For instance, in Zellmer v. Meta Platforms, Inc. (June 2024), the Ninth Circuit determined that Illinois’ Biometric Information Privacy Act (BIPA) didn’t apply because the facial recognition data wasn’t tied to identifiable individuals. On the flip side, in Rivera v. Google Inc., a federal court allowed BIPA claims to proceed, ruling that facial templates created from user images could still qualify as biometric identifiers, even without names attached.
But the challenges aren’t just legal – there are ethical dilemmas, too. Misidentification is one such issue, where someone might wrongly believe they recognize a real person in a synthetic dataset. Even if the data is entirely artificial, perceived harm can occur, such as when someone thinks they’ve uncovered a medical condition tied to a real person. As Michal Gal from the University of Haifa puts it:
"Synthetic data challenges the equilibrium found in existing laws which strike a balance between competing values, including data utility, privacy, security, and human rights".
To address these concerns, transparency is non-negotiable. Organizations need to document how synthetic data is generated, assess re-identification risks, and implement safeguards against reverse-engineering. As synthetic data becomes more integral to AI training, the demand for clear governance frameworks is only intensifying.
Conclusion
Synthetic data offers an alternative to traditional anonymization, but it comes with its own set of challenges. By creating entirely new records that replicate the statistical patterns of real data – without relying on actual records – it becomes especially useful for software testing, AI model training, and public data releases where sharing real information is restricted by legal or ethical constraints.
Deciding between synthetic and real data depends heavily on the context. For non-production environments like testing and development, synthetic data provides a safer choice, eliminating risks tied to exposing real data. However, when it comes to critical applications such as healthcare or finance, synthetic data alone may not be enough. To ensure privacy, it should be combined with techniques like differential privacy to guard against re-identification risks.
It’s important to acknowledge that synthetic data isn’t entirely "anonymous" in every scenario. Datasets containing rare attributes can still be susceptible to inference attacks. Moreover, the utility-privacy trade-off means that prioritizing privacy often comes at the cost of accuracy. Striking the right balance is key.
The takeaway? Synthetic data should be used thoughtfully, not as a one-size-fits-all solution. It shines in areas like augmenting underrepresented groups in training datasets, creating realistic testing conditions, and sharing aggregate insights with the public. However, handling sensitive information demands more than just synthetic data – it requires robust governance practices. This includes transparent documentation, regular bias assessments, and implementing privacy safeguards like differential privacy.
As the Stanford Technology Law Review succinctly puts it:
"Synthetic data is a valid, privacy-conscious alternative to raw data, but not a cure-all".
FAQs
Is synthetic data truly anonymous under U.S. privacy laws?
Synthetic data isn’t completely anonymous under U.S. privacy laws. Although it doesn’t rely on actual personal information, privacy risks can still emerge if it’s not managed properly. Mishandling synthetic data could potentially result in sensitive information being exposed, which underscores the importance of careful handling to reduce these risks.
How can synthetic data still lead to re-identification?
Synthetic data isn’t immune to privacy risks. Privacy attacks, such as reconstruction or membership inference, can still lead to re-identification. These methods may reveal specific details about individuals, even when privacy metrics indicate the data is secure. Simply applying differential privacy to the model doesn’t entirely eliminate these threats, as the generated datasets can still contain vulnerabilities.
When should you use real data instead of synthetic data?
Real data stands out when accuracy, detailed insights, and an exact reflection of actual events are non-negotiable. Synthetic data often struggles to fully reflect the complexity and subtle details of real-world situations, making real data indispensable for applications demanding a high level of precision or faithful replication of real-life scenarios.